在Git的手册上是这么描述的,它是一个傻瓜式的内容跟踪系统(stupid content tracker)。
Git应该是世界上使用最广的版本控制系统,令人奇怪的是,官方并没有将Git描述成”源码控制系统”。事实上,Git可以跟踪任何类型的内容,比如你可以创建一个基于Git的Nosql数据库。
之所以Git手册中说”傻瓜式”,是因为我们不需要对存储在Git中的内容做任何假设。Git的底层模型是相当基础的(basic)。在这篇文章中,我们将探索Git作为一个Nosql数据库(以key-value下那个是存储)的可能性。你可以将文件系统用来”数据存储”,然后用git add和git commit来保存文件:
# 保存文档
$ echo '{"id":1, "name":"legolas"}' > 1.json
$ git add 1.json
$ git commit -m "added a file"
# 读取文档
$ git show master:1.json
=> {"id":1, "name":"legolas"}
虽然实验成功了,但是无论我们储存什么,都是使用文件系统作为”database”:”path”的key-value形式。这样会有一些缺点:
- 在我们存储内容进git前,我们需要将所有的数据写入磁盘
- 我们需要多次保存数据
- “文件存储”并不是去重的,我们将失去git提供的”自动数据去重(deduplication)”
- 如果我们想同时在多分支上操作,我们需要多次切换我们的目录
我们想要的只是一个裸(bare)仓库,没有任何文件存在于文件系统中,而是在git数据库中。
将Git当作NoSQL数据库
Git是一套内容寻址(content-addressable)文件系统,从核心上来看不过是简单地存储键值对(key-value)。它允许插入任意类型的内容,并会返回一个可检索到该内容的键值,通过该键值可以在任何时候再取出该内容。
我们来创建一些内容:
# 初始化一个仓库
$ mkdir MyRepo && cd MyRepo
$ git init
# 存入内容
$ echo {"id": 1, "name": "kenneth"} | git hash-object -w --stdin
=> da95f8264a0ffe3df10e94eed6371ea83aee9a4d
初使化Git仓库时,Git初始化了objects目录,同时在该目录下创建了pack和info子目录,但是该目录下没有其他常规文件。通过底层命令hash-object将数据保存在.git目录并返回表示这些数据的键值。
hash-object是一个git管道命令(plumbing command),接收内容、将其存储在数据、然后返回键值。 参数-w(write)指示hash-object命令存储(数据)对象,若不指定这个参数该命令只会返回键值。参数-t指示对象的类型(默认是”blob”)。--stdin指定从标准输入设备(stdin)来读取内容,若不指定这个参数则需指定一个要存储的文件的路径。
该命令输出长度为40个字符的校验和。这是个SHA-1哈希值–其值为要存储的数据加上一种头信息的校验和。如果你按照上面的命令在你机器上执行,将会返回相同的sha-1哈希值。
Git存储数据内容的方式–为每份内容生成一个文件,取得该内容与头信息的SHA-1校验和,创建以该校验和前两个字符为名称的子目录,并以(校验和)剩下38个字符为文件命名 (保存至子目录下)。
# 查看.git目录下保存的文件
$ find .git/objects -type f
=> .git/objects/dc/bfa843bfc2c0039e79d2c272bc022312f31ceb
通过传递SHA-1值给cat-file命令可以让Git返回任何对象的内容和类型()该命令是查看Git对象的瑞士军刀)。传入-p参数美观地打印对象的内容,-t参数显示对象类型:
# 读取内容
$ git cat-file -p da95f8264a0ffe3df10e94eed6371ea83aee9a4d
=> {id: 1, name: kenneth}
# 显示类型
$ git cat-file -t da95f8264a0ffe3df10e94eed6371ea83aee9a4d
=> blob
简单描述下Git的四种对象类型:blob、tree、commit和tag:
blobs,每个blob代表一个(版本的)文件,blob只包含文件的数据,而忽略文件的其他元数据,如名字、路径、格式等。trees,每个tree代表了一个目录的信息,包含了此目录下的blobs,子目录(对应于子trees),文件名、路径等元数据。因此,对于有子目录的目录,git相当于存储了嵌套的trees。commits,每个commit记录了提交一个更新的所有元数据,如指向的tree,父commit,作者、提交者、提交日期、提交日志等。每次提交都只指向一个tree对象,记录了当次提交时的目录信息。一个commit可以有多个(至少一个)父commits。tags,tag来标记某一个提交(commit)的方法。
Git中BLOB对象
现在我们有一个键值对(key-value)存储在一个blob(binary large object)类型的对象中:
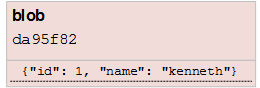
现在我们有一个问题: 我们不能更新它,因为如果我们更新这个内容,key将会变化。这意味着,对于文件的每个版本,我们不得不记住所有的key。而我们想要的是,指定自己的key用来跟踪每个版本。
Git中Tree对象
Trees对象解决了两个问题:
-
记住每个对象哈希值以及每个版本的需求
-
保存一系列文件的可能性
考虑tree的最好办法是类似于文件系统中的文件夹,按照下面的步骤创建一个tree:
# 创建一个文件,并暂存在暂存区(staging area)
$ git update-index --add --cacheinfo 100644 da95f8264a0ffe3df10e94eed6371ea83aee9a4d 1.json
# 将暂存区内容写入tree
git write-tree
=> d6916d3e27baa9ef2742c2ba09696f22e41011a1
这样也将返回一个sha哈希值,我们可以根据该哈希值读取tree:
$ git cat-file -p d6916d3e27baa9ef2742c2ba09696f22e41011a1
=> 100644 blob da95f8264a0ffe3df10e94eed6371ea83aee9a4d 1.json
到现在,我们存储在数据库中的对象如下:
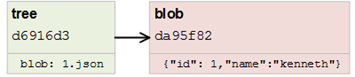
我们可以按照下面的步骤修改这个文件:
# 新增一个blob对象
$ echo "{"id": 1, "name": "kenneth truyers"}" | git hash-object -w --stdin
=> 42d0d209ecf70a96666f5a4c8ed97f3fd2b75dda
# 创建一个文件,并暂存在暂存区(staging area)
$ git update-index --add --cacheinfo 100644 42d0d209ecf70a96666f5a4c8ed97f3fd2b75dda 1.json
# 将暂存区内容写入tree
$ git write-tree
=> 2c59068b29c38db26eda42def74b7142de392212
现在数据库中是这样的情况:

现在数据库中有两个代表该文件不同状态的tree,这对于我们仍然没有太多帮助,因为我们还是需要记住tree的sha-1哈希值来获取内容。
Git根据某一时刻暂存区(即index区域,下同)所表示的状态创建并记录一个对应的树对象,如此重复便可依次记录(某个时间段内)一系列的树对象。
通过底层命令
update-index为一个单独文件的某个版本创建一个暂存区。 必须指定--add选项,因为此前该文件并不在暂存区中。 必需的还有--cacheinfo选项,将要添加的文件位于Git数据库中,而不是位于当前目录下 需要指定文件模式、SHA-1哈希值与文件名 文件模式为100644,表明这是一个普通文件;文件模式为100755,表示一个可执行文件;120000,表示一个符号链接。Git文件(即数据对象)的合法模式(当然,还有其他一些模式,但用于目录项和子模块) 通过write-tree命令将暂存区内容写入一个树对象。 无需指定-w选项–如果某个树对象此前并不存在的话,当调用write-tree命令时,它会根据当前暂存区状态自动创建一个新的树对象。
Git中commit对象
我们进一步,commit(提交)内容。一个commit包含5个关键信息:
- 提交的作者
- 创建的日期(时间戳)
- 为什么创建它(提交信息)
- 它所指向的单条tree对象
- 一条或者多条以前的commit(现在我们可以简单认为:commit只拥有单个父commit,拥有多个父commit的commit是合并提交(merge commit))
那我们来提交上面的那些tree:
# 提交第一个tree(没有父commit)
$ echo "commit 1st version" | git commit-tree d6916d3
05c1cec5685bbb84e806886dba0de5e2f120ab2a
# 提交第二个tree(父commit为前一个commit)
$ echo "Commit 2nd version" | git commit-tree 2c59068 -p 05c1cec5
9918e46dfc4241f0782265285970a7c16bf499e4
现在数据库中是下面的情况:

现在我们已经建立了关于这个文件的完整历史记录。使用任何git客户端打开这个仓库,都将看到1.json文件被正确跟踪。为了正面这一点,我们来看运行git log的输出:
$ git log --stat 9918e46
=> 9918e46dfc4241f0782265285970a7c16bf499e4 "Commit 2nd version"
1.json | 1 +
1 file changed, 1 insertions(+)
05c1cec5685bbb84e806886dba0de5e2f120ab2a "Commit 1st version"
1.json | 1 +
1 file changed, 1 insertion(+)
我们可以这样获得文件内容:
$ git show 9918e46:1.json
=> {"id": 1, "name": "kenneth truyers"}
这仍然没有达到要求,因为我们还是需要记住最后一次commit的哈希值。到目前为止,我们创建的所有对象都是git对象数据库的一部分,该数据库的特征是只存储不可变对象。一旦你写入一个blob、tree或者commit,我们并不能在不改变key的情况下修改该value。你也不能删除这些对象(至少不是直接删除他们,git gc命令可以删除悬空的(dangling)对象)。
Git引用
更进一步,是Git引用(references)。references不是对象数据库的一部分,它们是引用数据库(reference database)的一部分,并且是可变的。Git拥有不同类型的reference,例如branches、tags和remotes。它们本质相同,但是有一点细微的差异。现在,我们来研究下branches。分支(branch)是一个指向commit的指针。我们可以通过创建一条新的分支(branch),将commit的哈希值写入文件系统:
echo "05c1cec5685bbb84e806886dba0de5e2f120ab2a" > .git/refs/heads/master
现在我们已经创建好了一个新分支(branch),指向我们的第一条commit。想要移动分支(branch),我们可以执行下面的命令:
git update-ref refs/heads/master 9918e46
现在我们就得到下面这样的图像:
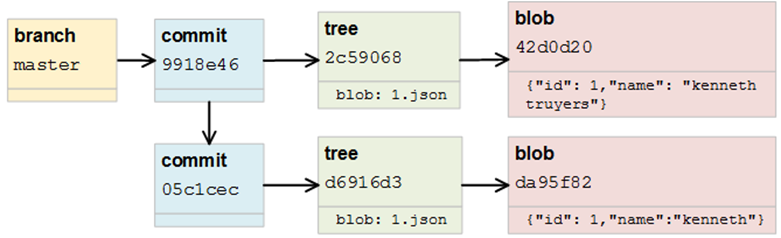
最后,我们可以读取该文件的当前状态:
$ git show master:1.json
=> {"id": 1, "name": "kenneth truyers"}
即使我们添加新版本的文件、一系列的tree和commit,只要我们将branch指针指向最新的commit,上面的命令仍将继续有效。
对于简单的键值存储来说,上面的这些操作似乎有点复杂。然而,我们可以抽象这些,以便于客户端只需要指定一个branch和一个key。不过这些,我会在以后的文章中讲述。现在我们来讨论”使用Git作为Nosql数据库”的潜在优点和缺点
数据效率
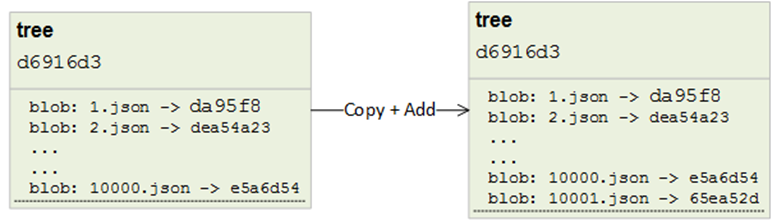
Git用来存储数据时效率是非常高的。如前所述,相同内容的blob只会存储一次,因为计算出的哈希值一致。我们可以尝试将一大堆相同内容的文件添加到一个空仓库,然后检查.git目录的大小和文件在磁盘的大小。你将会发现,.git目录相当小。
但是不仅仅是这些,Git处理tree也是一样。如果你修改一个子级树(subtree)中的文件,git将只创建一个新的tree,并且只引用其他没有受影响的tree。下面的示例,显示了一个指向具有两个子目录的层次结构的commit:

如果我们现在想要去替换blob4658ea84,git将只替换那些修改的项目,并且保留那些没有修改的项目作为reference。用不同的文件替换blob合并提交更改后,图像将如下所示(新的对象被标记为红色):
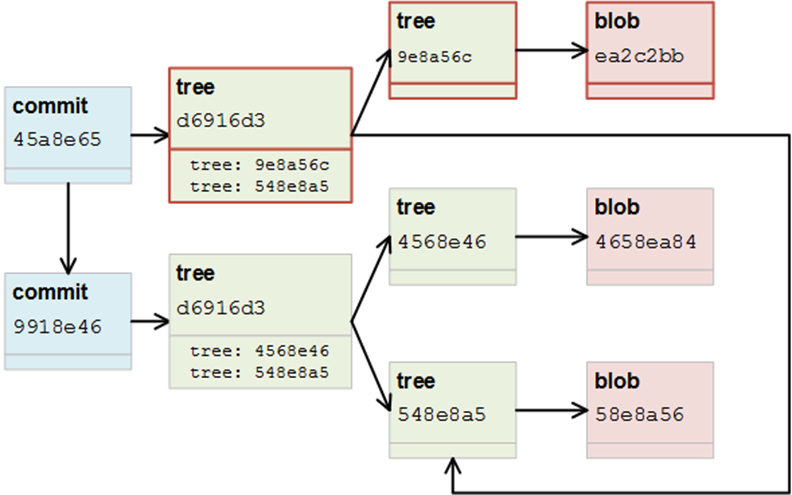
由此可见,git只是替换了一些必须的部分,并且引用了已存在的项目。
虽然git在引用已存在数据方面非常高效,但是如果每一个小修改都将产生一个完整的副本,那么一段时间之后我们将会得到一个非常大的仓库。为了缓解这一点,Git拥有一个自动垃圾回收处理。当运行git gc时,它会检查你的blob。在可能时,它会删除这些blobs,取而代之的是存储一个基础数据的单独副本,连同blob的每个版本的修改。这样,git仍然能检索每个不同的版本,而不需要多次存储这些数据。
版本控制
我们可以免费获得完整的版本控制系统。这样的版本控制具有不删除数据的优点。我们在SQL数据库中见过这样的例子:
id | name | deleted
1 | kenneth | 1
像这样的简单记录是没问题的,但是这通常只是冰山一角。数据可能对其他数据有依赖关系(是否是外键只是一个实现细节),当你想要恢复数据时,可能在隔离数据上存在风险。对于gi而言,只是一系列指向不同的commit的分支,能以数据库级别而不是记录级别将数据恢复到正确状态。
我们来看另外一个:
id | street | lastUpdate
1 | town rd | 20161012
这种例子很少碰到:你知道它已经被更新,但是没有任何信息关于实际更新内容以及以前的数值。每当你更新数据,你其实是在删除数据,并且插入了一条新的数据,旧的数据就永远丢失了。使用Git,你可以对于任何文件运行git log,可以看到什么被修改,谁修改了它,什么时候修改,以及为什么修改。
Git工具集
Git拥有丰富的工具集,用以浏览和操作数据。其中大部分工具服务于代码,但并不意味着不能用来处理其他数据。以下是一些我能想到的不太详尽的工具概览:
使用这些基础的Git命令:
- 使用
git diff查找两个commit/branch/tag等之间的确切变化。 - 使用
git bisect来查明某些由于数据更改而导致不能正常运行的原因。 - 使用
git hooks来获取自动更改通知、构建全文检索、更新缓存、发布数据等。 - 还有
git revert,git branch,git merge…
除此之外还有些外部工具:
- 可以使用Git客户端来浏览可视化数据
- 可以使用Github上的”pull requests”,在合并前检查数据变更
- Gitinspector: 基于git仓库的统计分析
任何能搭配git工具,都能用在数据库上。
NoSQL
由于是键值(key-value)存储,可以得到NoSQL存储的常见优点,例如无模式数据库。可以存储任何想要保存的数据,甚至不一定是JSON格式。
连接
Git可以在网络分区中工作。你可以将东西存放在U盘上,当离线的时候保存数据,在线的时候推送提交并且合并数据。我们经常在开发的时候这么使用,在某些情况下它能救命。
事务
在上面的例子中,我们提交了文件的每一次更改。不一定非要这么做,你也可以将多次变更作为一个commit提交。这样以后可以很容易原子性回滚。
事务持久化(long lived)也是可以实现的:可以创建一个branch,提交若干更改,然后合并(或者丢弃)。
备份和同步
对于传统数据库而言,创建一个全备份和增量备份定时任务,通常有点麻烦。由于Git存储的是整个历史,数据库不需要做全备份。此外,备份其实就是一次简单的git push。这些推送可以到达任何地方,GitHub、BitBucket或者自托管的git服务器。
复制也同样简单。使用git hooks,你可以设置一个触发器,在每次commit之后运行git push:
$ git remote add replica git@replica.server.com:app.git
$ cat .git/hooks/post-commit
#!/bin/sh
...
$ git push replica
这些简直太棒了,我们应该从现在开始全部使用Git作为数据库!稍等。还有一些缺点。
查询
我们可以通过key来查询。唯一的好消息是,我们可以在文件夹中构造你的数据,通过这种方式可以很很容易地通过前缀来获取内容。除非你想完整的递归搜索,任何其他的查询方式都是禁用的。这里唯一的选项是专门用于查询的索引。如果不关心数据是否过期,可以在预计的基础数据上这么做,或者在每次提交的时候可以使用git hooks去更新索引。
并发
并发写入blobs,是没有任何问题的。当我们开始编辑commit和更新branch时,才会出现并发问题。下图可以说明,当两个进程同时去创建commit时出现的问题:
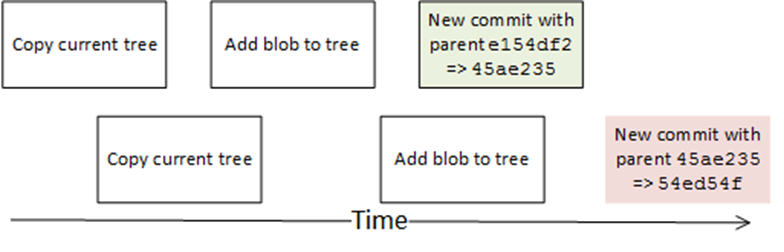
上面的例子中,当第二个进程修改了tree的副本和更改时,它其实是工作在一个已过期的tree上。当其提交这个tree时,将会丢失第一个进程所做的更改。
同样的情况也使用于移动branch头。在提交和更新branch头的间隙,另一个commit可能会进入,我们可能会将branch头更新到错误的commit。
解决这个问题的唯一办法是,在读取当前树的副本和更新branch头时,加写入锁。
速度
众所周知,Git速度很快,但是这只是在创建branch的背景下。其实提交的每一秒并不是很快,因为我们一直在对磁盘进行写入。因为我们在写代码时通常不会做多次提交(至少我不会),所以我们没有注意到这一点。在经过我本地机器上进行测试后,可以得出限制大概是110commits/s。
Brandon Keepers在几年前的一个视频中展示过一些结果,大概限制是90commits/s,这个差异可能是硬件进步造成的。
110commit/s对于大部分应该来说是足够,但并不是对于所有的都是这样。这只是针对我本地开发机器上一些资源的一个理论值。还有很对可能影响速度的因素,后文会讲:
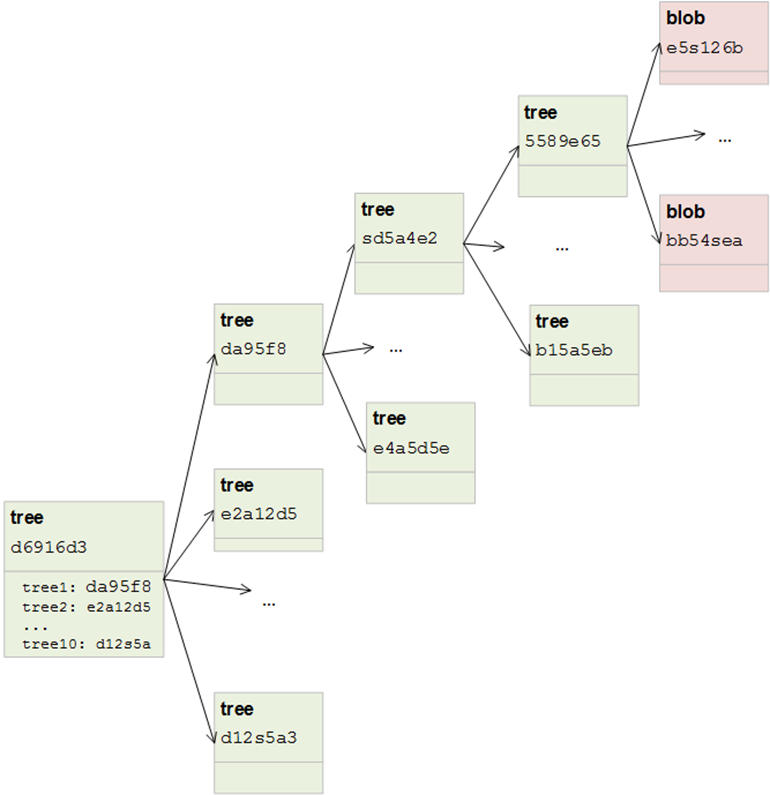
Tree规模
一般来说,我们应该偏好使用一些子目录,而不是将所有文档全放在一个目录。这样可以尽可能将写入速度接近最大值。因为我们每次创建一个新的commit,都必须复制这个tree,做对应修改后保存修改后的tree。虽然你可能认为这样会影响tree的大小,事实上并不是这样,因为运行git gc将只会保存一个增量而不是两个不同的tree。我们可以看这样的一个例子:
第一种情况,在根目录下存储有10000个blob对象。当我们添加一个文件,我们会复制一个包含10000个项目的tree,然后添加一个项目并且保存。由于tree的大小,这可能是个长时间操作。
第二种情况,有四个层次的tree,每个节点有10个子树,在最后层次每个节点对应10个blob(10 * 10 * 10 * 10 = 10000个文件)。
这种情况下,如果我们想添加一个blob,不需要复制整个层次结构,只需要复制该blob所在的分支。下图将会显示,必须复制和修改的tree:
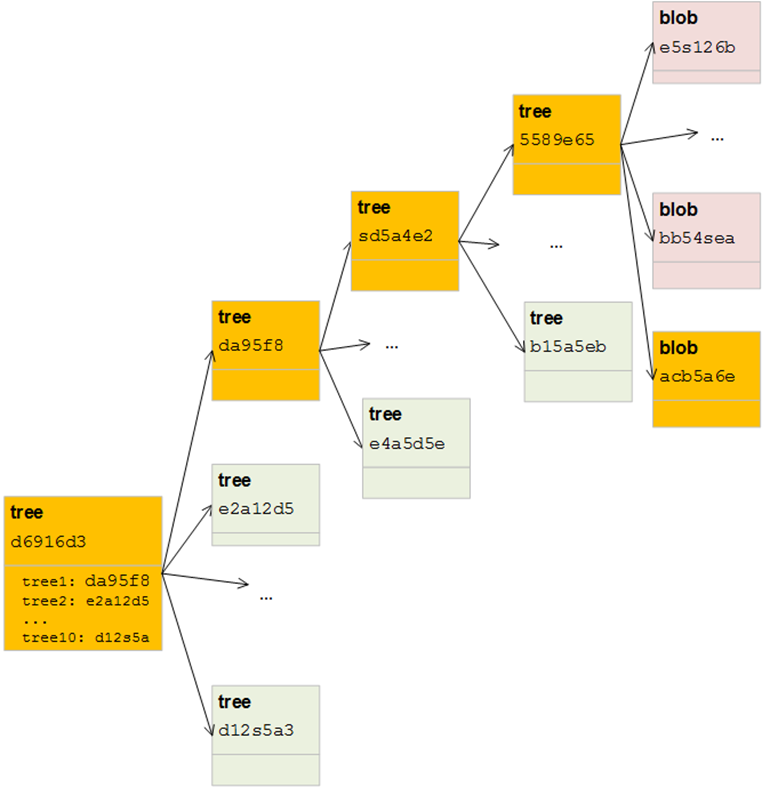
所以我们可以不用去复制10000条目的一个tree,而是通过使用子目录,只用复制包含10条目的5个tree,这样会快很多。当数据增长越多,我们越应该使用子目录。
将数值组合成事务
如果我们想要每秒超过110个提交,而且不需要能够单独回滚它们。在这种情况下,我们应该在一个commit中提交多个更改,而不是每次更改都做一个commit。这样可以同时写入多个blob,因此可以实现1000个文件并发写入磁盘,然后执行一次提交后将它们都存储到仓库中。虽然这样有很多缺点,但是想要读写速度,只是唯一的办法。
这个问题的解决方案是,给Git添加另一个后端,它不会立即刷新内容到磁盘,而是首先写入内存数据库,然后异步刷新到磁盘。实现这个并不是很简单,我使用libgit2sharp库连接仓库去测试这个解决方案时,我是将Voron作为后端(开源项目,也是ElasticSearch的变体)。这将会提升相当多的速度,但是你失去了使用标准git工具去检索数据的便利。
合并
当从不同分支合并数据时,可能会存在另一个问题。如果没有合并冲突,实际上是一次相当愉快的体验,可以用在很多场景:
- 在生效前,修改需要审核的数据
- 在需要还原的实时数据上,进行测试
- 在合并数据前,隔离工作
事实上,在开发过程中使用branch,你会得到所有这些乐趣。但是,在存在合并冲突时,我们会遇到麻烦。合并数据其实相当负责,因为我们并不是一直能解决这些合并冲突。
一个可行的策略,当写数据时存储合并冲突,当读数据时向用户展示差异,以便用户能选出正确的数据。然而,怎么去正确地管理这些数据,是个艰巨的任务。
总结
在某些情况下,git是很好的NoSQL数据库。它有其局限性,但是我认为在以下方面git特别实用:
- 层级结构数据(得益于其天生的层次性)
- 能在离线环境下工作
- 数据需要审核机制(也可以说是,需要分支和合并)
在其他情况下,git并不是太适用:
- 需要极端的写入性能
- 需要负责查询(虽然可以通过提交钩子来建立索引去解决)
- 拥有庞大的数据量(写入速度会更慢)
以上就是如何使用Git作为NoSQL数据库。
推荐
noms是一个基于Git思想的分布式数据库
来源: